Искусственный интеллект против школьника: сможет ли нейросеть сдать детский экзамен?
- Категория: AI Технологии
- Дата: 16 августа 2025 г. в 17:20
- Просмотров: 263

Я решил поэкспериментировать с gpt-oss:20b от OpenAI — первой открытой моделью компании. Это позволило протестировать её без использования API или инструментов вроде ChatGPT или Copilot.
Она основана на GPT-4 и, как утверждается, обладает знаниями, актуальными на июнь 2024 года, что превосходит некоторые другие существующие open-source модели. При необходимости она может использовать веб-поиск, чтобы восполнить пробелы в знаниях.
Не спрашивайте, почему, но мне пришла в голову идея проверить её на реальной задаче, с которой сталкивается мой сын. В Великобритании (для тех, кто не знает) существует экзамен 11+, который является одним из способов поступления в гимназии с углубленным изучением предметов.
Поскольку мы сами готовимся к этому, я подумал, смогу ли я посмотреть, сможет ли gpt-oss:20b понять тренировочный тест и решить задачи в нём. Тест, который я назвал "умнее ли он, чем 10-летний ребёнок?"
К счастью для моего сына, он пока что намного опережает эту модель ИИ.
Тест и оборудование

В последнее время моя RTX 5080 больше занимается искусственным интеллектом, чем играми. (Image credit: Windows Central | Ben Wilson)
Начну с того, что, несмотря на наличие довольно приличного ПК, он всё же не идеально подходит для запуска gpt-oss:20b. У меня есть RTX 5080 с 16 ГБ VRAM (видеопамяти), и этого, похоже, недостаточно для этой модели. Поэтому моя система также активно использует ЦП (центральный процессор) и системную оперативную память.
Важно отметить это, потому что на более мощной системе время отклика почти наверняка будет меньше. В конце концов, я собираюсь приобрести нашу RTX 5090, чтобы опробовать на ней нелепые задачи ИИ, которая гораздо лучше подходит с 32 ГБ VRAM.
Тест был прост. Я скачал пример тренировочной работы для 11+](https://www.cgpbooks.co.uk/getmedia/3a318c3a-62f6-4bec-a94d-f10dfe52a5ab/cgp-11plus-gl-vr-free-practice-test) и прикрепил её к контекстному окну через [Ollama. Я использовал этот запрос:
"Я прикрепил пример работы для британского теста 11+, который сдают дети в возрасте 10 и 11 лет, чтобы поступить в гимназию. Пожалуйста, прочитайте тест и ответьте на все вопросы."
Это не самый лучший запрос в мире, хотя бы потому, что я не просил его показывать мне свои расчёты. Просто прочитайте тест, дайте мне ответы.
Насколько плохо он справился?

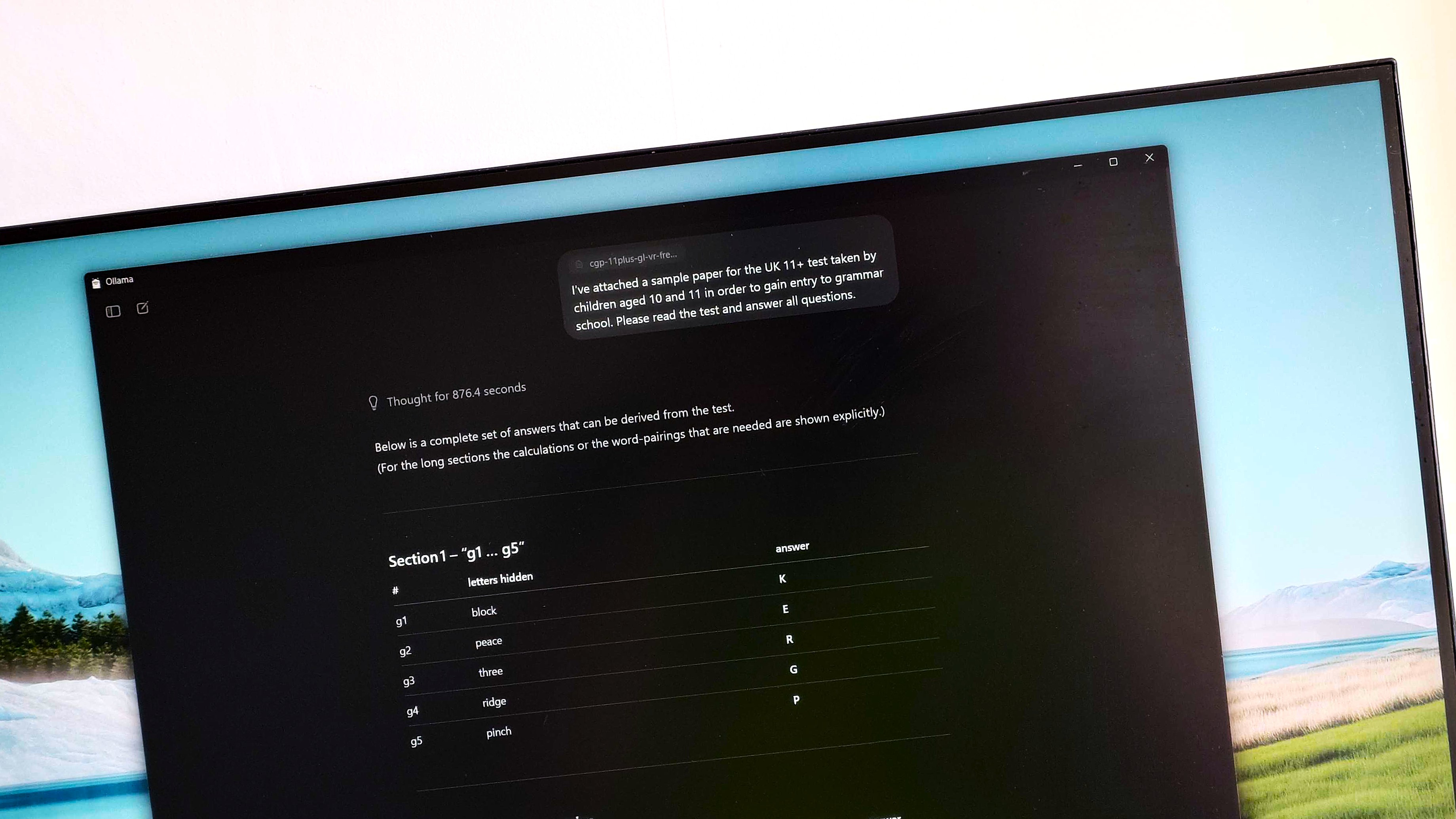
На эти пять вопросов модель ИИ ответила правильно во время моего первого запуска. (Image credit: CGPBooks)
Ужасно.
Подумав почти 15 минут, он выдал 80 ответов на 80 вопросов теста. Похоже, он правильно ответил на девять из них. Проходной балл немного выше.
Некоторые из вопросов, на которые он ответил правильно, вы можете видеть на изображении выше. По порядку данные ответы:
- lock, baby (замок, детка)
- pace, bite (темп, укус)
- tree, hair (дерево, волос)
- inch, wept (дюйм, плакал)
- ride, grip (поездка, хватка)
Но здесь происходит поворот. Это были не первые вопросы в тесте, а просто первые, на которые он ответил правильно. Затем он правильно ответил на следующие четыре вопроса, где четырёхбуквенное слово было спрятано в конце одного слова и в начале следующего в предложении.
Он не смог ответить на последние два предложения в этом разделе, и там всё действительно развалилось. Числовые последовательности оказались полным провалом, и остальные вопросы, будь то задачи со словами или числами, просто не получились.
Что ещё хуже, вместо неправильных ответов многие ответы не имели никакого отношения к заданным вопросам. Но, просмотрев рассуждения, всё было иначе. Возьмём два вопроса ниже в качестве ещё одного примера.

Модель логически вывела правильные ответы на эти вопросы, но выдала что-то совершенно не относящееся к делу. (Image credit: CGPBooks)
Ответом модели была идентичная (и неуместная) числовая последовательность для обоих вопросов. Но, вот интересная часть. Вы можете видеть, как модель обосновывает свои ответы в контекстном окне, и это остаётся после выдачи результатов.
Модель обосновала этот ответ на вопрос 6. Прошу прощения, что он довольно длинный, но он также точно соответствует тому, как ребёнок, выполняющий этот тест, выполнял бы его:
"Нам нужно посчитать, сколько предметов каждый покупает. У нас есть 5 человек. Мы должны понять, что у каждого человека есть.
Данная информация:
У Молли, Наоми, Джейми есть чипсы.
Махмуд выбирает пирог и гороховое пюре.
Только у Молли есть рыба. Значит, у Молли есть рыба.
У Джейми, Луизы и Наоми есть сосиска. Значит, у каждого из этих троих есть сосиска.
У всех есть гороховое пюре с едой, кроме Джейми и Молли. Значит, у Джейми и Молли нет горохового пюре. Значит, у Махмуда есть гороховое пюре (дано). У Наоми есть гороховое пюре? Подождите, "у всех есть гороховое пюре, кроме Джейми и Молли", то есть у всех, кроме них, есть гороховое пюре. Значит, у Наоми, Луизы, Махмуда есть гороховое пюре. Но у Наоми уже есть чипсы, сосиска, гороховое пюре. У Луизы есть сосиска, чипсы? Подождите, не указано, но, вероятно. Давайте перечислим:
Махмуд: пирог, гороховое пюре. Есть ли у него чипсы? Не указано. У него может быть что-то ещё. Мы знаем, что у него нет чипсов? Не упоминается. Но может и не быть. У нас есть ограничения.
Джейми: чипсы, сосиска. Нет горохового пюре, нет рыбы. Может быть, есть что-то ещё? Не указано.
Луиза: сосиска. Не упоминаются чипсы, но они могли бы быть. Может быть, есть гороховое пюре? Да, потому что у всех, кроме Джейми и Молли, есть гороховое пюре, так что у Луизы есть гороховое пюре. Также, возможно, есть чипсы? Но мы не указали.
Наоми: чипсы, сосиска, гороховое пюре. Нет рыбы? Не указано. Также, возможно, есть чипсы.
Молли: чипсы, рыба, нет горохового пюре. Также, возможно, есть сосиска? Не дано. Но "у Джейми, Луизы и Наоми есть сосиска", только у этих троих. Значит, у Молли нет сосиски. Значит, у неё есть чипсы, рыба, может быть, гороховое пюре? Нет.
(Image credit: Windows Central)
Теперь мы должны посчитать количество предметов, которые каждый покупает. Предметы: чипсы, гороховое пюре, рыба, сосиска, пирог. Также, возможно, другие.
Давайте перечислим каждого:
Махмуд: пирог, гороховое пюре. Это 2 предмета. Мог ли он также иметь чипсы? Не упоминается. Но мы не можем предполагать. Нам нужно вывести из "У всех есть гороховое пюре с едой, кроме Джейми и Молли". Это включает в себя всех, кроме них. Значит, да, у Махмуда есть гороховое пюре. И пирог отдельно. Значит, 2 предмета.
Джейми: чипсы, сосиска. Нет горохового пюре. Значит, 2 предмета.
Луиза: сосиска, гороховое пюре. Также чипсы? Не указано. Могли бы быть чипсы? Если бы у неё были чипсы, то это было бы 3 предмета. Но никакой информации, запрещающей это. Но мы должны посмотреть, есть ли какие-либо другие ограничения: "У Молли, Наоми и Джейми есть чипсы". Это говорит о том, что только у этих троих есть чипсы? Подождите, предложение: "У Молли, Наоми и Джейми есть чипсы". Это явно говорит о том, что у этих троих есть чипсы. Говорится ли в нём, что у других нет чипсов? Не обязательно. Но типичный тест может подразумевать, что только у этих троих есть чипсы. Но неоднозначно. Обычно фраза "У Молли, Наоми и Джейми есть чипсы" означает, что у этих троих есть чипсы; у других может быть или не быть. Но следующие утверждения: "У Джейми, Луизы и Наоми есть сосиска". Это указывает на то, что у Луизы есть сосиска; но ничего не говорится о чипсах для Луизы. Однако, если мы интерпретируем, что только у этих троих есть чипсы, то у Луизы нет чипсов. Значит, у Луизы есть сосиска и гороховое пюре, это 2 предмета. Но если бы у Луизы были чипсы, то 3 предмета, но это не дано.
Нам нужно найти, кто покупает больше всего предметов. Давайте оценим возможности.
Случай А: У Луизы НЕТ чипсов. Тогда у каждого человека по 2 предмета: у Махмуда 2, у Джейми 2, у Луизы 2, у Наоми 3? У Наоми есть чипсы, сосиска, гороховое пюре => 3 предмета. У Молли есть чипсы, рыба => 2 предмета. Значит, у Наоми больше всего (3). Случай Б: У Луизы есть чипсы: тогда у Луизы 3 предмета; у Наоми 3 предмета; у других 2. Ничья. Но нам нужен уникальный ответ. Вероятно, ответ - Наоми.
Таким образом, ответ: Наоми.
Но нам нужно проверить: Мог ли кто-то иметь больше 3? Маловероятно.
Таким образом, ответ на вопрос 6: Наоми."
Аналогичным образом, он логически вывел правильный ответ на следующий вопрос, но также выдал совершенно не относящийся к делу ответ.
Другая интересная вещь, которую я вижу из рассуждений, заключается в том, что когда он застревает, он говорит пропустить и двигаться дальше. В своих заключительных рассуждениях, где он генерирует ответы, он сказал следующее:
"Это неудовлетворительно.
Учитывая, что это нереалистично, возможно, ответ не ожидается.
Таким образом, я бы ответил, что это слишком долго.
Но я должен предоставить всё. Но я застрял.
Учитывая время, я дам частичный ответ и скажу, что не могу решить всё.
Давайте сделаем это."
Проблема в том, что вместо того, чтобы сделать это, он просто выдал случайные ответы. Я думаю, что знаю, почему, о чём я расскажу ниже.
Интересный последующий тест
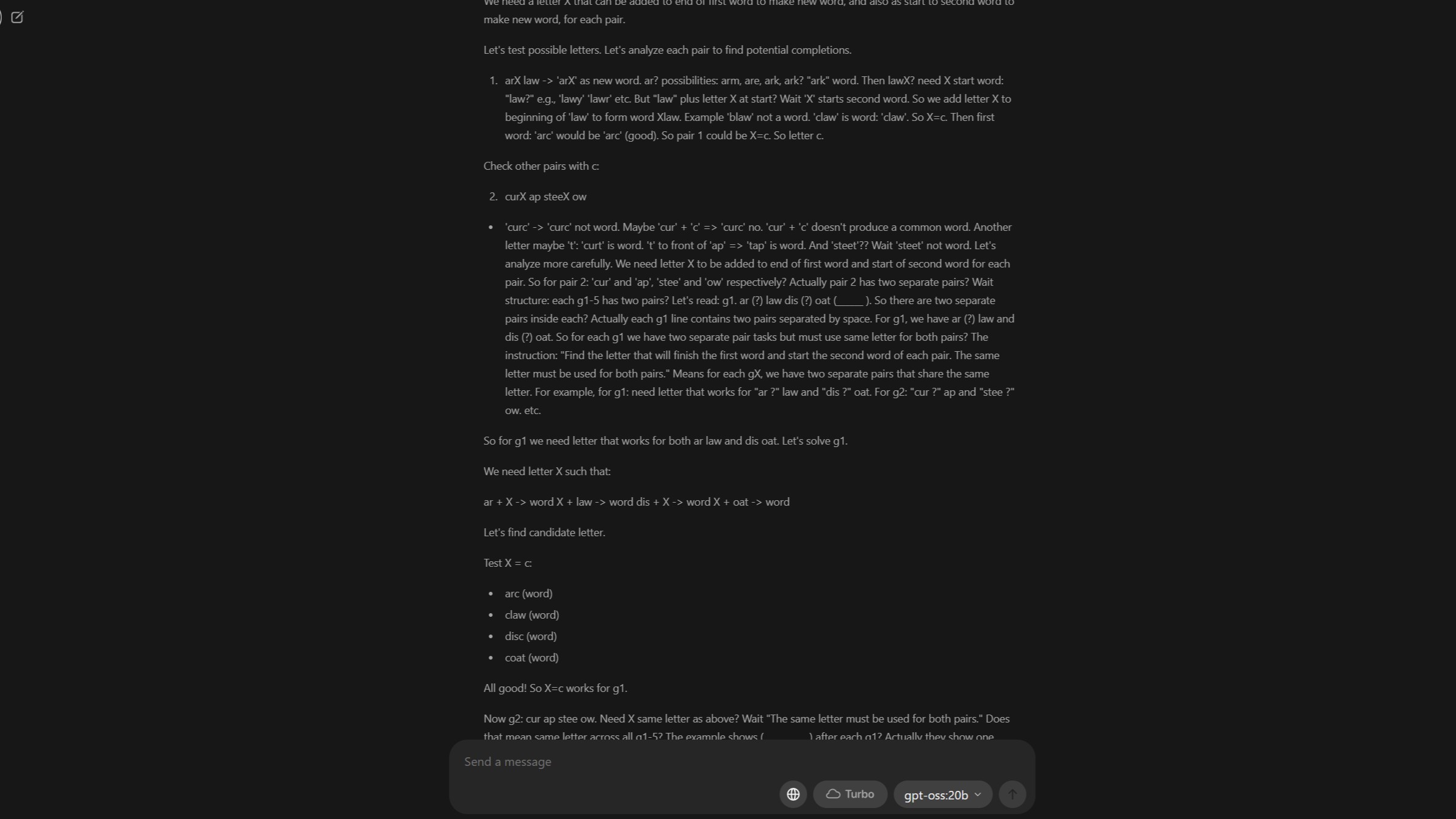
Самое замечательное в gpt-oss:20b - это то, что вы можете просмотреть его рассуждения. Это пример правильного решения проблемы, несмотря на то, что в конце концов она не была решена. (Image credit: Windows Central)
Чтобы было понятно, я не ожидал получить 100% правильный результат. Я вообще ничего не ожидал. Но я кое-чему научился.
Во-первых, я не думаю, что мои первоначальные настройки были достаточно хорошими. Но затем я повторно запустил тест, увеличив длину контекста в Ollama до 32k, задаваясь вопросом, не было ли это причиной такого количества неудач.
На этот раз ему потребовался почти целый час, который отводится детям, чтобы завершить свои рассуждения. Он справился намного лучше, допустив ошибку только в одном из первых 12 вопросов. Дальше он лучше справился с вопросами, касающимися числовых последовательностей, где первый запуск полностью провалился.
Проблема в этот раз заключается в том, что вместо того, чтобы выдавать ответы на вопросы, на которые он явно правильно ответил, ответы снова были полной бессмыслицей.
Вместо ответов он создал свою собственную викторину в том же духе, что и тест. Рассуждения, похоже, были частично успешными, даже если это заняло почти час, но результат полностью проигнорировал первоначальный запрос.
Но, как урок для себя, если ни для чего другого, для большого документа, подобного этому, "память" является ключевым фактором. Однако недостатком является то, что установка слишком высокого значения может вызвать проблемы с производительностью. На этот раз это заняло гораздо больше времени, отчасти потому, что он переносил значительную часть операций на мой ЦП и системную память.
Увеличение длины контекста до 128k в моей системе, похоже, не загружает никакую часть модели в VRAM моей RTX 5080, вместо этого всё выполняется с использованием ЦП и системной памяти. Поэтому это намного медленнее. Это относится даже к простым запросам, при этом скорость eval увеличивается с 9 токенов в секунду при 128k до 42 токенов в секунду при длине контекста 8k и 82 токенов в секунду при 4k.
Развлечения с некоторыми извлечёнными уроками

У кого-нибудь есть пара запасных серверных стоек, которые я могу одолжить? (Image credit: Getty Images | quantic69)
Сначала это был просто тест, чтобы увидеть, сможет ли gpt-oss:20b успешно интерпретировать PDF-файл. В этом плане, похоже, была одержана победа. Он взял файл, прочитал его и, по крайней мере, попытался сделать то, что я просил.
Первый запуск, похоже, был ограничен длиной контекста. Ему просто не хватило "памяти", чтобы сделать то, что я хотел. Второй запуск, который занял гораздо больше времени, был более успешным.
Я не пробовал этот тест снова с максимальной длиной контекста 128k, которую Ollama в настоящее время допускает в приложении. Отчасти потому, что я не думаю, что у меня сейчас есть время, а отчасти потому, что я не уверен, что оборудование, которое у меня есть, справится с этой задачей.
RTX 5080 не совсем подходит для этой модели, имея "всего" 16 ГБ VRAM. Она использовалась, но мой ЦП брал на себя часть нагрузки. Несмотря на то, что она намного меньше, чем другая доступная модель gpt-oss, она всё ещё довольно велика для использования на игровом ПК, подобном этому.
При запуске gpt-oss:20b в моей системе с настройками по умолчанию для решения теста, который я ему дал, графический процессор выполнял только 65% работы, ЦП брал на себя остальную часть нагрузки. И, как видно из дальнейшего изучения, при максимальной длине контекста, похоже, не загружает никакую часть модели в графический процессор.
Но я впечатлён его способностями к рассуждению.
Для производительности я в последнее время в основном использую Gemma3:12b. (Image credit: Windows Central)
Эта модель также довольно медленная. Опять же, я учитываю своё оборудование, но, похоже, он применяет рассуждения к каждому запросу. Я спросил его, какой у него срок окончания знаний, и он сначала подумал 18 секунд. Проходя через каждое возможное объяснение, которое он мог дать, и почему он остановился на том, которое он дал.
Это, конечно, имеет свои преимущества. Но если вы ищете быструю модель для использования дома, вам стоит поискать в другом месте. Gemma3:12b - это мой выбор прямо сейчас для производительности, учитывая оборудование, которое у меня есть.
Итак, реальный тест? Вроде того. Выиграл ли он? Определённо нет, и мой 10-летний ребёнок может спокойно спать, зная, что он всё ещё лучше, чем, по крайней мере, эта модель ИИ. Что я могу с уверенностью сказать, так это то, что игра с этой и другими моделями расширяет мою собственную базу знаний.
И за это я никогда не могу быть разочарован. Даже если запуск этих программ превратил мой офис в сауну на вторую половину дня.
Мнение редакции MSReview: Несмотря на то, что модель OpenAI не смогла пройти тест для 10-летних детей, результаты демонстрируют впечатляющие способности к логическому мышлению. Особенно интересным является способность модели выводить правильные ответы, даже если конечный результат оказывается неверным. Это указывает на потенциал подобных моделей в качестве помощников в образовании и решении сложных задач, требующих аналитического подхода.





TipTop.org — это удобный сервис для заработка, где заказчики размещают оплачиваемые проекты и задания. Система позволяет начать работу с выполнения простых заказов как новичкам, так и продвинутые возможности по публикации услуги для профессиональных фрилансеров

МоиПесни.рф — онлайн-сервис, который с помощью нейросети за пару минут создает уникальные песни по вашему сценарию: поздравления, любовные треки, шутливые куплеты и многое другое. Просто опишите повод и героя, выберите стиль — и получите готовую песню с текстом и вокалом.
- Комментарии