Локальный ИИ: нужен ли вам монстр-компьютер? История одного семилетнего ноутбука
- Категория: AI Технологии
- Дата: 13 августа 2025 г. в 14:20
- Просмотров: 309

Принято считать, что для работы с ИИ локально на компьютере требуется мощное железо. В этом есть доля правды, но, как и в случае с играми, все относительно. Многие современные игры можно запустить как на Steam Deck, так и на ПК с RTX 5090. Опыт будет разным, но главное – играть можно.
То же самое и с локальными ИИ-инструментами, например, с запуском больших языковых моделей (LLM) с помощью Ollama. Конечно, мощная видеокарта с большим объемом видеопамяти (VRAM) – это идеально, но не обязательно.
Вот вам пример: мой семилетний Huawei MateBook D с уже довольно слабеньким AMD Ryzen 5 2500U, 8 ГБ оперативной памяти и без дискретной графики. И он все еще справляется с Ollama, может загружать некоторые LLM, и, я бы сказал, вполне пригоден для работы.
Ограничения запуска ИИ на старом железе
Сравнение с играми здесь очень уместно. Чтобы получить максимум от новейшего и самого требовательного контента, вам нужно серьезное железо. Но вы также можете наслаждаться многими современными играми на старых и менее мощных машинах, даже на тех, которые используют только интегрированную графику.
Но есть нюанс: старое, менее мощное железо просто не будет работать так же хорошо. Скорее всего, вам придется довольствоваться 30 кадрами в секунду (FPS) вместо (как минимум) 144 FPS, но это возможно. Придется пожертвовать настройками графики, трассировкой лучей и разрешением.
То же самое и с ИИ. Вы не будете выдавать сотни токенов в секунду и не сможете загружать самые новые и большие модели.
Но есть много небольших моделей, которые вы вполне можете попробовать, как это сделал я, успешно, на старом железе. Если у вас есть совместимая видеокарта – отлично, она будет использоваться. У меня ее нет, но я все равно добился определенных успехов.
В частности, я загрузил несколько моделей размером 1b (1 миллиард параметров) в Ollama на своем старом ноутбуке, на котором сейчас установлена Fedora 42. Мой APU (Accelerated Processing Unit) официально не поддерживается Windows 11, но я обычно использую Linux на старом железе.
Ollama – кроссплатформенное решение, существуют версии для Mac и Windows, а также для Linux. Так что неважно, что вы используете; даже старый Mac может с этим справиться.
Насколько это "юзабельно"?
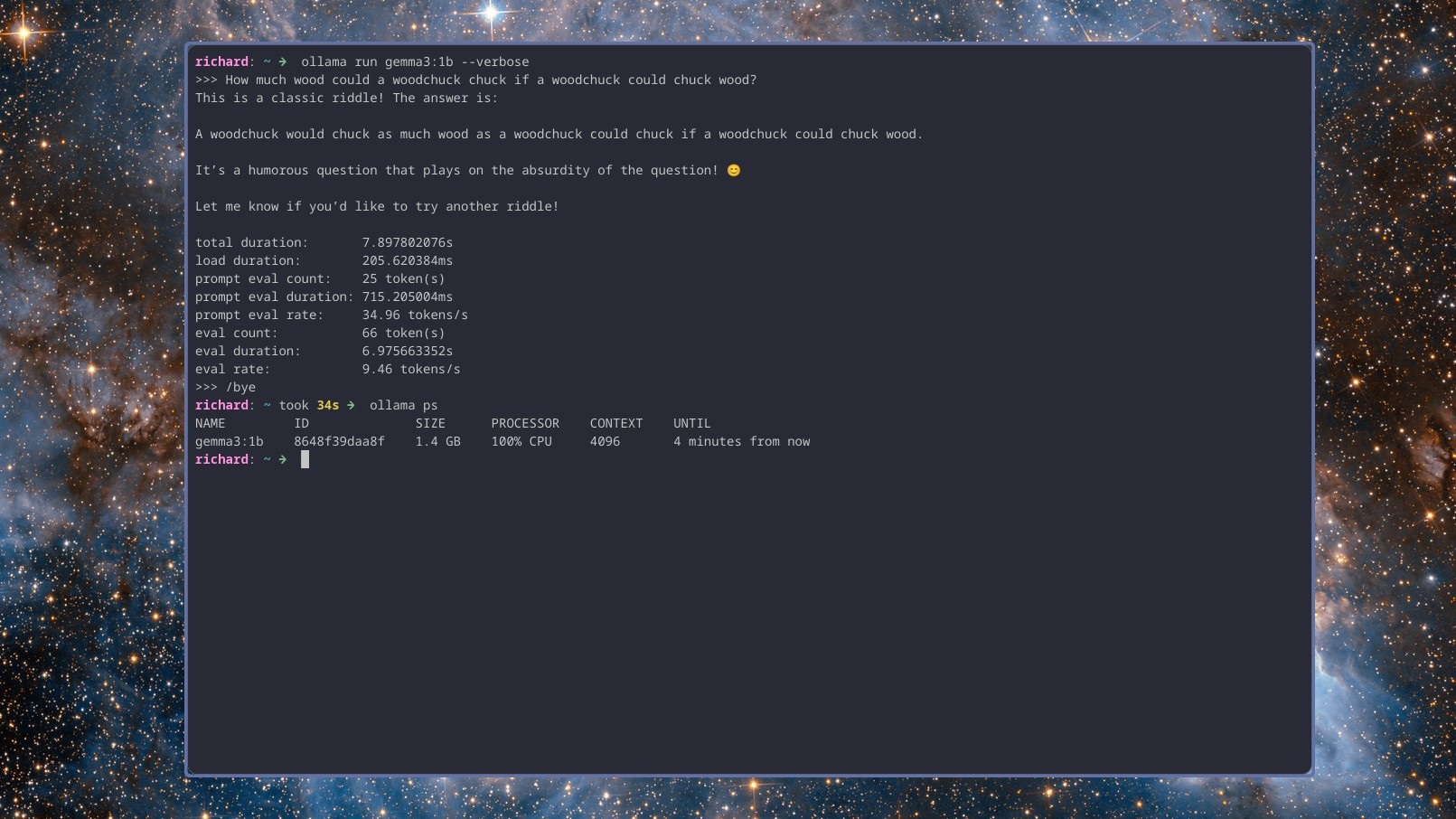
Я не пробовал модели больше 1b на этом ноутбуке, и не думаю, что это стоит потраченного времени. Но тестирование трех таких моделей – gemma3:1b, llama3.2:1b и deepseek-r1:1.5b – дало схожие результаты. Во всех случаях LLM используют длину контекста 4k, и я не думаю, что стоит рисковать и пробовать что-то большее.
Начнем с моего старого фаворита:
"Сколько дров наломает дровосек, если бы дровосек мог ломать дрова?"
Gemma 3 и Llama 3.2 выдали короткий, довольно быстрый ответ и показали чуть менее 10 токенов в секунду. Deepseek r1, напротив, обладает способностью к рассуждению, поэтому сначала обдумывает процесс, затем дает ответ, и немного отставал – чуть менее 8 токенов в секунду.
Но, хотя это и не быстро, это вполне пригодно для использования. Все три модели выдают ответы значительно быстрее, чем я могу печатать (и определенно быстрее, чем я могу думать). И это все с длиной контекста 4k.
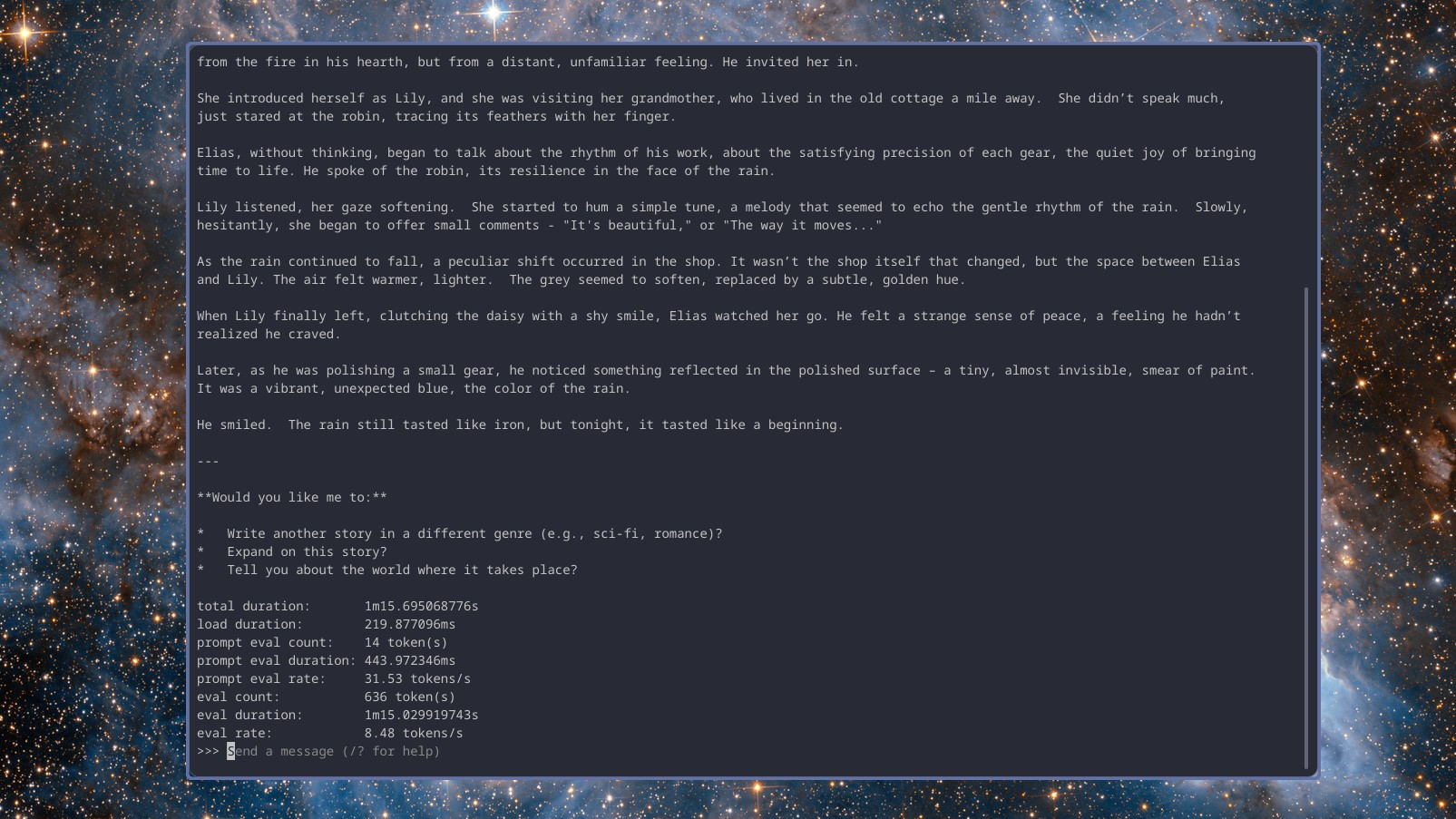
Второй тест был немного сложнее. Я попросил все три модели сгенерировать простой скрипт PowerShell для получения необработанного содержимого текстовых файлов из репозитория GitHub, а также задать вопросы, чтобы убедиться, что я доволен результатом, чтобы создать наилучший возможный скрипт.
Обратите внимание, я не проверял, работает ли вывод на самом деле. В данном случае меня интересует только то, насколько хорошо (и быстро) модели справляются с задачей.
Gemma 3 выдала очень подробный вывод, объясняющий каждую часть скрипта, задавая вопросы по ходу дела, чтобы адаптировать скрипт, и все это со скоростью чуть менее 9 токенов в секунду. DeepSeek r1 с рассуждениями работал немного медленнее, опять же, 7,5 токенов в секунду, но не задавал вопросов. Llama 3.2 выдала результат, аналогичный по качеству Gemma 3, со скоростью чуть менее 9 токенов в секунду.
Ах да, я еще не упомянул, что все это происходило при работе от аккумулятора со сбалансированным планом питания. При подключении к внешнему источнику питания все три модели практически удвоили количество токенов в секунду и выполняли задачу примерно в два раза быстрее.
Думаю, это более интересный момент. Вы можете находиться в дороге с ноутбуком, работающим от аккумулятора, и все равно выполнять задачи. Дома или в офисе, подключенные к сети, даже старое оборудование может быть вполне работоспособным.
Все это было сделано исключительно с использованием ЦП и оперативной памяти. Ноутбук выделяет пару гигабайт оперативной памяти для использования iGPU, но даже в этом случае она не поддерживается Ollama. Быстрый ollama ps показывает 100% загрузку ЦП.
Это небольшие LLM, но правда в том, что вы можете с ними поиграть, интегрировать их в свой рабочий процесс, получить некоторые навыки, и все это без разорения на новом, безумно мощном оборудовании.
Не нужно далеко ходить на YouTube, чтобы найти авторов, запускающих ИИ на Raspberry Pi и домашних серверах, состоящих из старого и (теперь) более дешевого оборудования. Даже со старым ноутбуком среднего уровня вы, вероятно, сможете хотя бы начать.
Это не ChatGPT, но это что-то. Даже старый ПК может быть AI PC.
Мнение редакции MSReview: Не стоит списывать со счетов старое оборудование. Даже если у вас нет новейшей видеокарты, вы все равно можете экспериментировать с локальными AI-инструментами, особенно с небольшими моделями. Это отличный способ начать знакомиться с технологией и понять, как она может быть полезна в вашей работе или учебе.





TipTop.org — это удобный сервис для заработка, где заказчики размещают оплачиваемые проекты и задания. Система позволяет начать работу с выполнения простых заказов как новичкам, так и продвинутые возможности по публикации услуги для профессиональных фрилансеров

МоиПесни.рф — онлайн-сервис, который с помощью нейросети за пару минут создает уникальные песни по вашему сценарию: поздравления, любовные треки, шутливые куплеты и многое другое. Просто опишите повод и героя, выберите стиль — и получите готовую песню с текстом и вокалом.
- Комментарии