Секрет быстрой работы локального ИИ Ollama в Windows: ошибка, которую совершают многие
- Категория: AI Технологии
- Дата: 12 августа 2025 г. в 17:20
- Просмотров: 824
Недавно я увлекся Ollama – способом запускать ИИ прямо на своем компьютере с Windows 11. И дело не только в любопытстве, есть веские причины предпочесть локальный ИИ таким сервисам, как ChatGPT или Copilot.
Конечно, учеба – это всегда здорово, мне интересно, как работают новые технологии, и как их можно применить на практике.
Но в эти выходные я получил ценный урок о производительности. Ollama недавно выпустила новое приложение с графическим интерфейсом, которое упрощает работу с ИИ, без необходимости возиться с терминалом или сторонними расширениями.
Тем не менее, терминал остается полезным инструментом, и именно там я понял, что мои локальные ИИ-модели работают не так быстро, как могли бы.
Все дело в длине контекста.
Длина контекста: ключ к скорости ИИ
Что такое длина контекста и как она влияет на скорость работы ИИ? Длина контекста (или окно контекста) – это максимальный объем информации, который модель может обработать за один раз.
Проще говоря, большая длина контекста позволяет модели "помнить" больше деталей из разговора, обрабатывать крупные документы и, как следствие, повышать точность.
Но есть и обратная сторона: большая длина контекста требует больше ресурсов и замедляет время ответа. Контекст измеряется в токенах – единицах текста. Чем больше текста, тем больше ресурсов нужно для его обработки.
Ollama поддерживает длину контекста до 128k, но если у вас недостаточно мощное "железо", ваш компьютер может сильно "тормозить". Я убедился в этом, когда пытался запустить gpt-oss:20b для решения теста, предназначенного для детей 10-11 лет.
В этом примере короткая длина контекста не дала модели достаточно информации для обработки всего теста, а большая – замедлила работу.
У ChatGPT длина контекста превышает 100 000 токенов, но у него есть преимущество в виде мощных серверов OpenAI.
Правильная длина контекста для каждой задачи – залог высокой скорости
Постоянно менять длину контекста может быть немного утомительно, но это значительно повышает эффективность работы моделей. Я не обращал на это внимания, пока не понял, в чем дело.
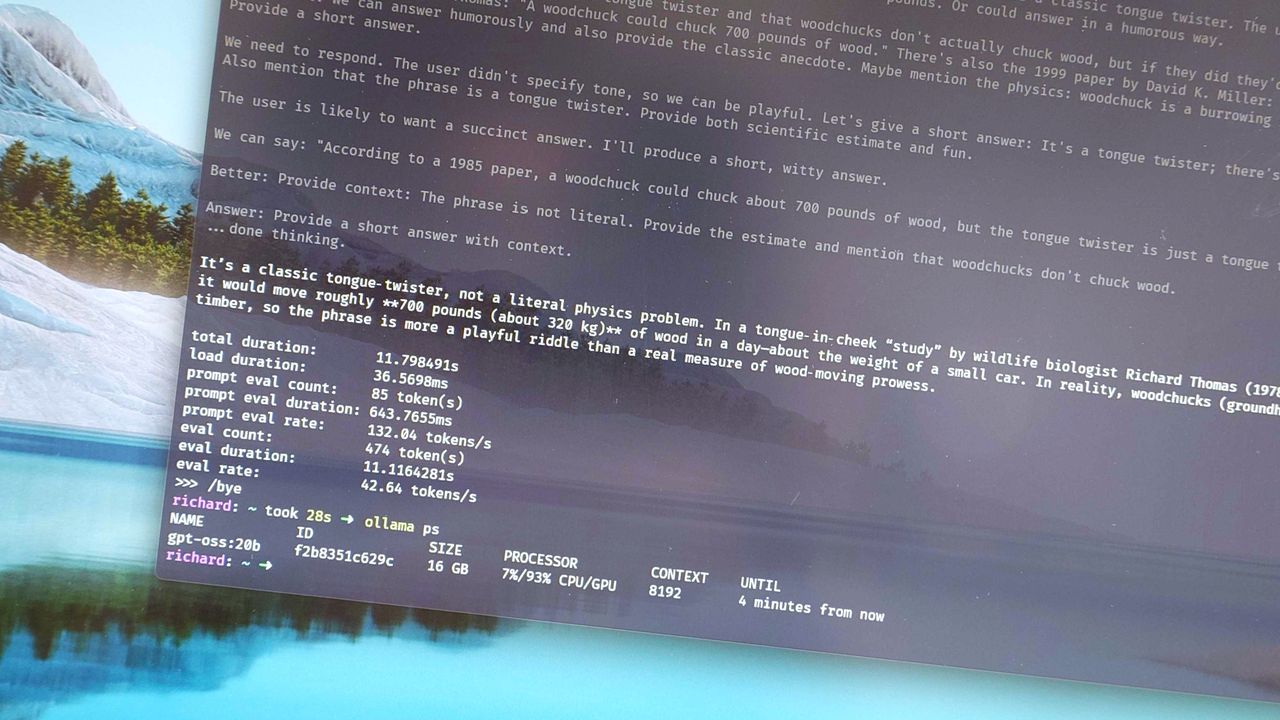
До меня это дошло, когда я экспериментировал с настройками Ollama в терминале, чтобы оценить скорость работы модели. Я не знал, что для gpt:oss20b установлена длина контекста 64k, и был удивлен, получив скорость всего 9 токенов в секунду на простой вопрос:
"Сколько дров заготовил бы сурок, если бы сурок мог заготавливать дрова?"
При этом видеокарта не использовалась, модель работала только на процессоре и оперативной памяти. Уменьшив длину контекста до 8k, я получил скорость 43 токена в секунду. А при 4k скорость удвоилась до 86 токенов в секунду.
Кроме того, при 4k видеокарта использовалась на полную мощность, а при 8k – на 93%.
Суть в том, что если вам не нужно обрабатывать большие объемы данных или вести очень длинные разговоры, установка меньшей длины контекста значительно повысит производительность.
Важно найти баланс между тем, что вы хотите получить от сеанса, и длиной контекста, которая справится с этим наиболее эффективно.
Как изменить длину контекста в Ollama и сохранить ее для будущего использования
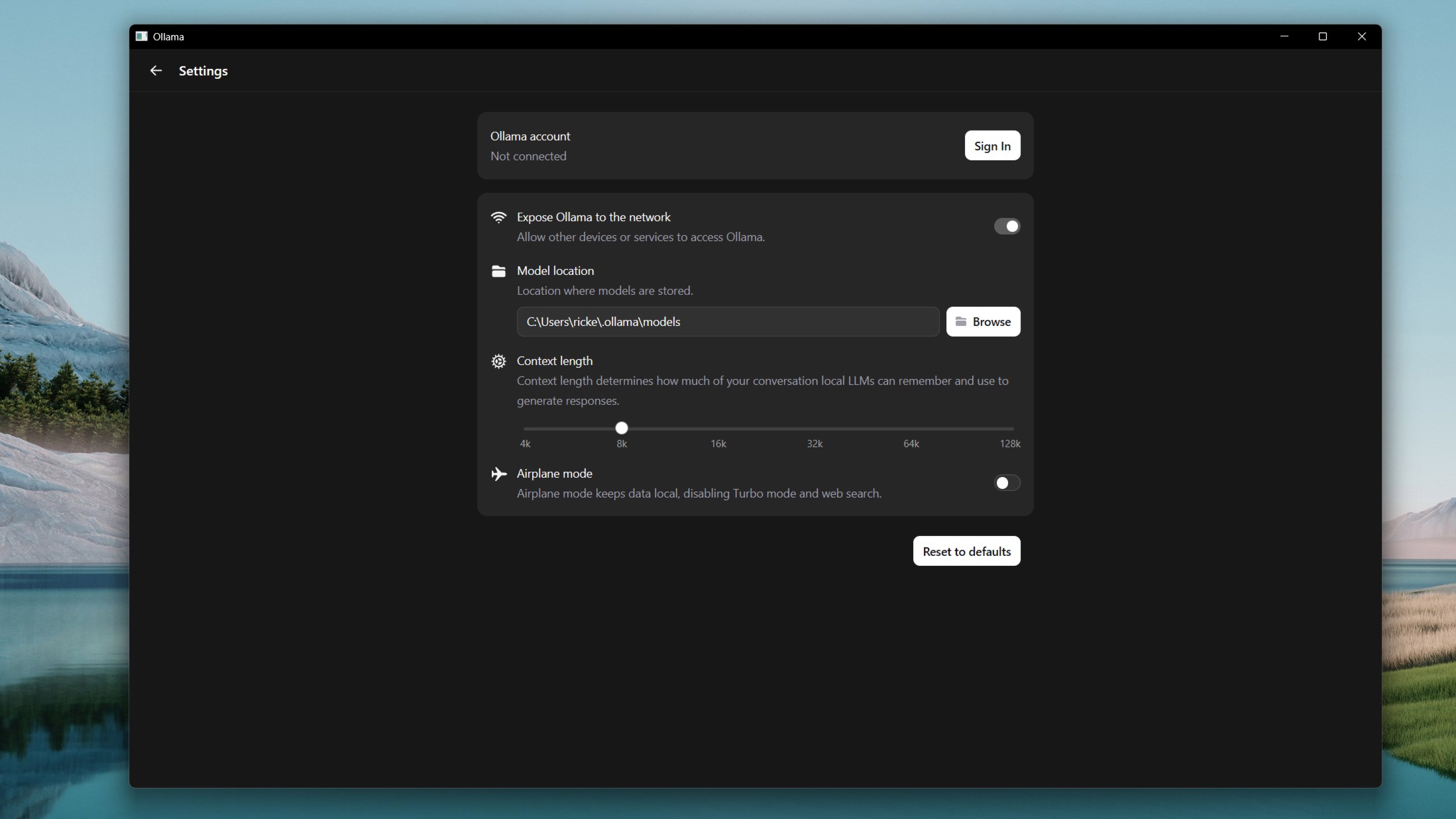
Изменить длину контекста в Ollama можно двумя способами: через терминал и через новое приложение с графическим интерфейсом.
Второй вариант проще. Просто зайдите в настройки и перемещайте ползунок между 4k и 128k. Недостаток в том, что это фиксированные значения; нельзя выбрать что-то промежуточное.
Но если вы используете терминал, Ollama CLI дает больше свободы в выборе точной длины контекста, а также позволяет сохранить версию модели с этой длиной.
Зачем это нужно? Во-первых, у вас будет модель с фиксированной длиной контекста; вам не придется постоянно ее менять. Это удобно. Во-вторых, у вас может быть несколько "версий" модели с разной длиной контекста для разных задач.
Чтобы это сделать, откройте PowerShell и запустите нужную модель с помощью команды:
ollama run
Когда модель запущена, измените длину контекста, используя следующий формат. Здесь я устанавливаю длину контекста 8k:
/set parameter num_ctx 8192
Число в конце – это желаемая длина контекста. Теперь вы будете использовать эту длину, но если вы хотите сохранить версию, введите команду:
/save
Теперь вы можете запускать эту сохраненную модель через CLI, графическое приложение или использовать ее в других интеграциях с Ollama.
Недостаток в том, что чем больше версий вы создаете, тем больше места на диске они занимают. Но если у вас достаточно места, это удобный способ не думать об изменении длины контекста.
Вы можете установить низкое значение для максимальной производительности при выполнении небольших задач, или более высокое – для более сложных.
Как проверить производительность модели в Ollama
В заключение покажу, как увидеть распределение нагрузки между процессором и видеокартой, а также количество токенов в секунду, которое выдает модель.
Рекомендую поэкспериментировать с этим, чтобы найти оптимальные значения для вашей модели и вашего оборудования.
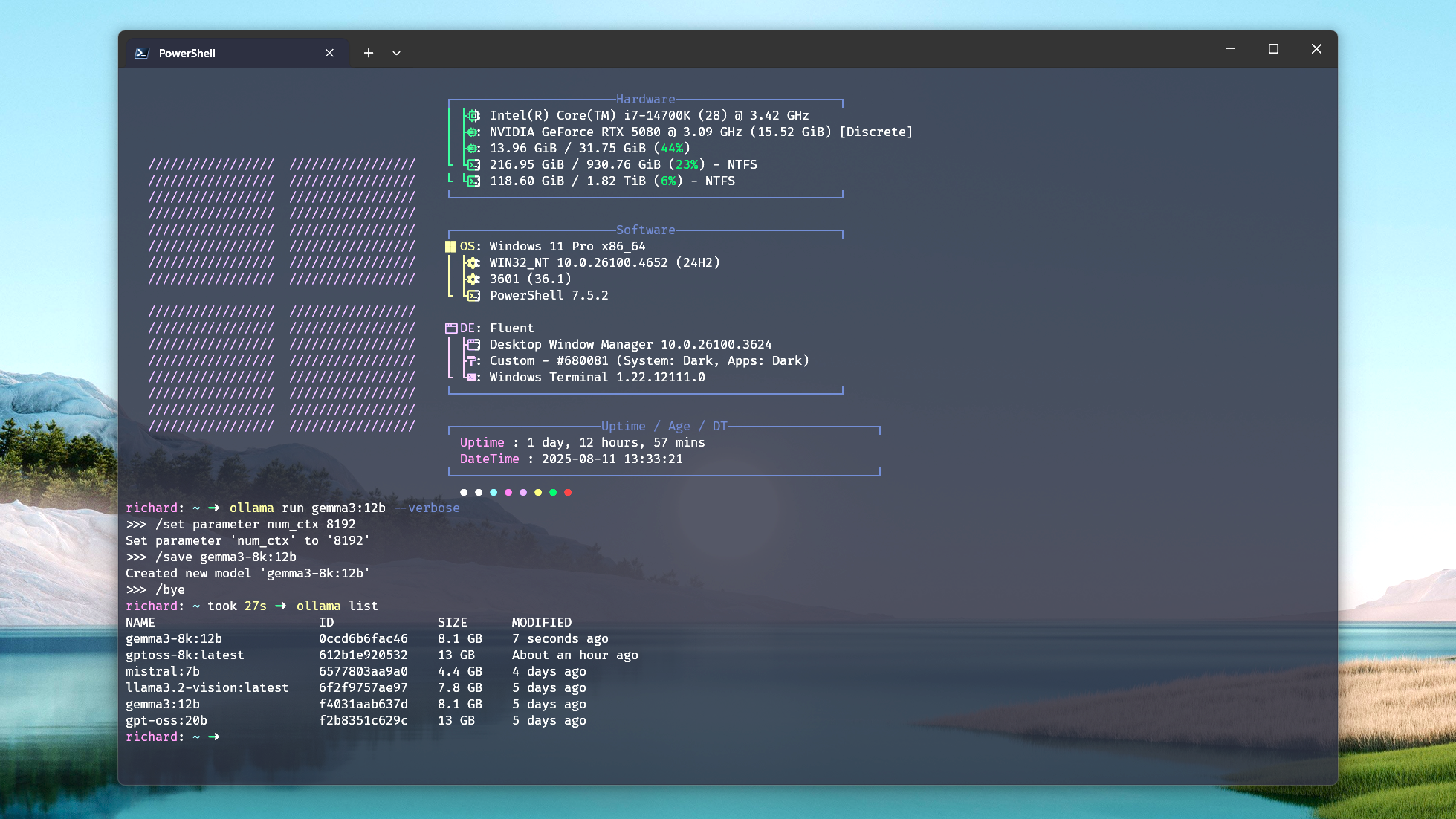
Если у вас установлен только Ollama и нет сторонних инструментов, вам понадобится терминал. При запуске модели добавьте тег --verbose к команде. Пример:
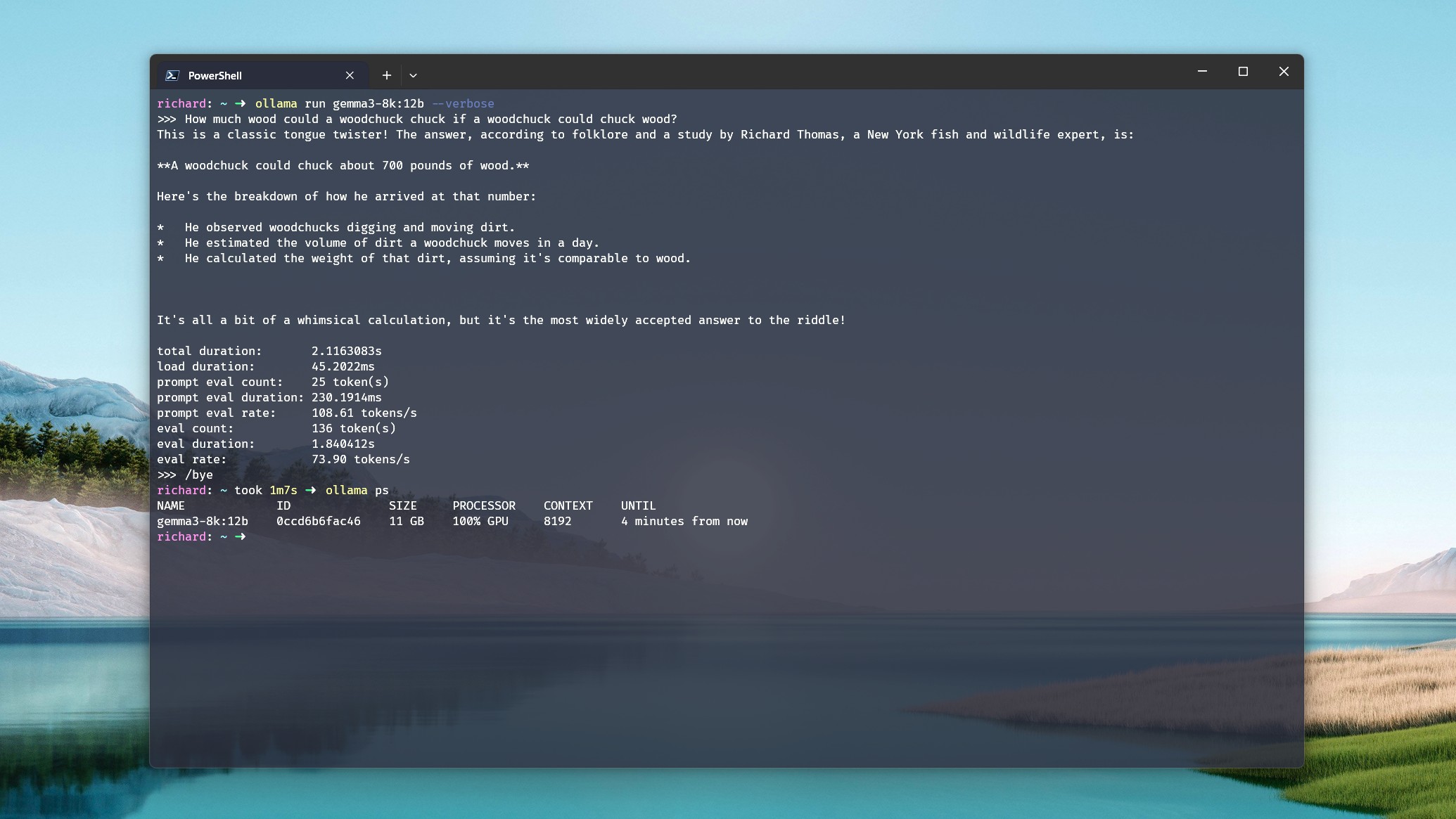
ollama run gemma3:12b --verbose
Эта команда генерирует отчет с показателями производительности после ответа. Самый простой показатель – eval rate (токены в секунду). Чем он выше, тем лучше производительность.
Чтобы увидеть распределение нагрузки между ЦП и графическим процессором, выйдите из модели с помощью команды /bye. Затем введите ollama ps, и вы увидите процент использования ЦП и графического процессора. В идеале, вы хотите, чтобы процент использования графического процессора был 100% или как можно ближе к этому значению.
Например, в моей системе с RTX 5080 мне нужно установить длину контекста ниже 8k для gpt-oss:20b, чтобы использовать 100% мощности видеокарты. При 8k это "всего" 93%, но это все равно отлично.
Надеюсь, это поможет новичкам в Ollama, потому что я сам упустил этот момент. С мощной видеокартой я просто предположил, что все будет работать быстро само по себе.
Но даже с RTX 5080 мне пришлось скорректировать свои ожидания и длину контекста, чтобы добиться максимальной производительности. Я не скармливаю моделям огромные документы, поэтому мне не нужна огромная длина контекста для коротких запросов.
Я рад совершать ошибки, чтобы вам не пришлось этого делать!
Мнение редакции MSReview: Оптимизация длины контекста в Ollama может значительно повысить производительность локальных LLM. Экспериментируйте с различными значениями, чтобы найти баланс между точностью и скоростью для ваших конкретных задач.






TipTop.org — это удобный сервис для заработка, где заказчики размещают оплачиваемые проекты и задания. Система позволяет начать работу с выполнения простых заказов как новичкам, так и продвинутые возможности по публикации услуги для профессиональных фрилансеров

МоиПесни.рф — онлайн-сервис, который с помощью нейросети за пару минут создает уникальные песни по вашему сценарию: поздравления, любовные треки, шутливые куплеты и многое другое. Просто опишите повод и героя, выберите стиль — и получите готовую песню с текстом и вокалом.
- Комментарии