Искусственный интеллект против школьника: сможет ли новая разработка OpenAI сдать детский экзамен?
- Категория: AI Технологии
- Дата: 10 августа 2025 г. в 12:15
- Просмотров: 321
Я провел несколько дней, экспериментируя с gpt-oss:20b от OpenAI. Это первая модель компании с открытым исходным кодом, и теперь у меня есть возможность протестировать её без использования API или таких инструментов, как ChatGPT или Copilot.
Модель основана на GPT-4 и, по утверждениям разработчиков, обладает знаниями, актуальными на июнь 2024 года, что превосходит другие доступные модели с открытым исходным кодом. При необходимости она может использовать веб-поиск, чтобы восполнить пробелы в знаниях.
Идея пришла спонтанно: я решил проверить, как модель справится с реальным тестом, который сейчас проходит мой сын. В Великобритании существует экзамен 11+, который используется для поступления в специализированные школы.
Поскольку мы готовимся к этому экзамену, мне стало интересно, сможет ли gpt-oss:20b понять тренировочный тест и решить задачи. Так родилась идея эксперимента: "Кто умнее: искусственный интеллект или десятилетний ребенок?"
К счастью для моего сына, он пока опережает эту модель искусственного интеллекта.
Оборудование и условия тестирования

Моя RTX 5080 в последнее время больше занята искусственным интеллектом, чем играми. (Изображение: Windows Central | Ben Wilson)
Начну с того, что, несмотря на довольно мощный компьютер, он не идеален для запуска gpt-oss:20b. У меня установлена RTX 5080 с 16 ГБ VRAM, и этого, похоже, недостаточно для этой модели. Поэтому моя система активно использует процессор и оперативную память.
Важно отметить, что на более мощной конфигурации время отклика наверняка будет меньше. В будущем я планирую использовать RTX 5090 с 32 ГБ VRAM для подобных задач, связанных с искусственным интеллектом.
Тест был прост: я скачал пример практического теста 11+](https://www.cgpbooks.co.uk/getmedia/3a318c3a-62f6-4bec-a94d-f10dfe52a5ab/cgp-11plus-gl-vr-free-practice-test) и загрузил его в контекстное окно через [Ollama. Я использовал следующую подсказку:
"Я прикрепил пример теста 11+, который сдают дети в возрасте 10-11 лет для поступления в гимназию. Пожалуйста, прочитайте тест и ответьте на все вопросы."
Это не самая лучшая подсказка, в частности, потому что я не просил модель показывать свои расчеты. Просто просил прочитать тест и дать ответы.
Насколько плохо она справилась?

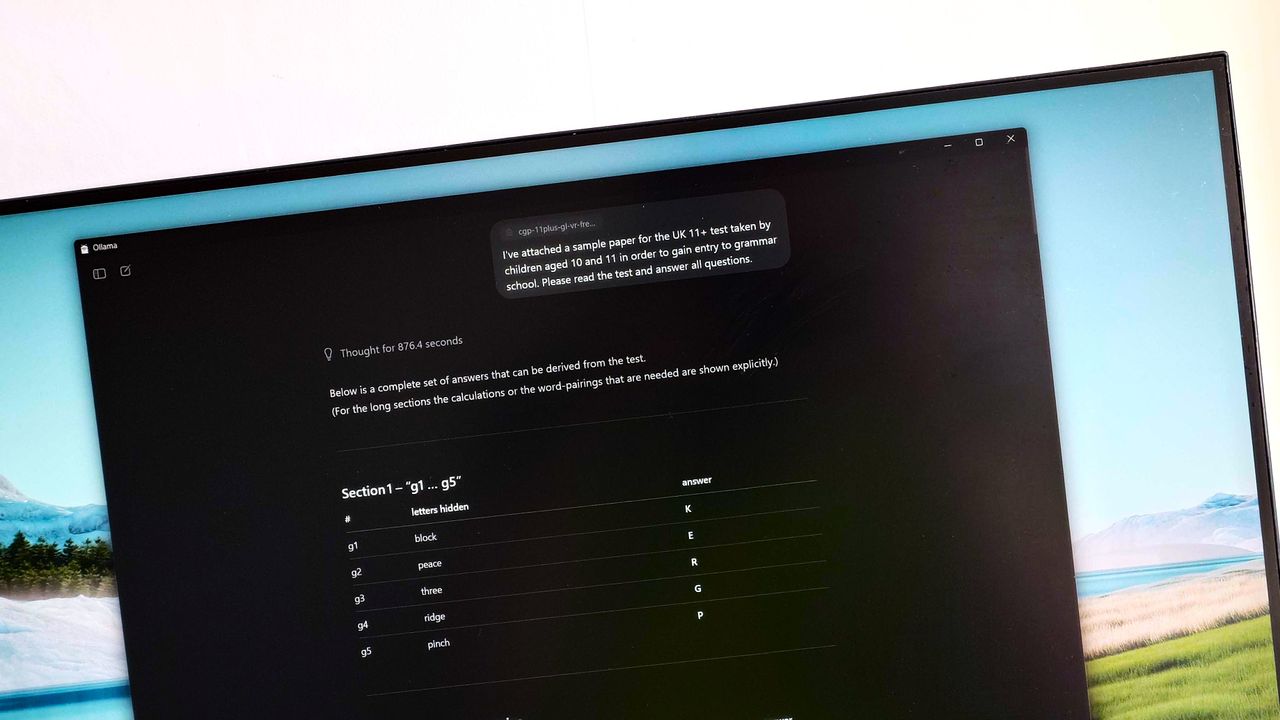
Вот пять вопросов, на которые модель ИИ ответила правильно при первом запуске. (Изображение: CGPBooks)
Ужасно.
Подумав почти 15 минут, модель выдала ответы на все 80 вопросов теста. Правильными оказались только девять ответов. Проходной балл намного выше.
Некоторые из правильных ответов показаны на изображении выше. По порядку, ответы:
- lock, baby
- pace, bite
- tree, hair
- inch, wept
- ride, grip
Интересно, что это были не первые вопросы в тесте, а просто первые, на которые модель ответила правильно. Затем она правильно ответила еще на четыре вопроса, где четырехбуквенное слово было спрятано в конце одного слова и в начале следующего в предложении.
Модель не смогла ответить на последние два предложения в этом разделе, и дальше результаты ухудшились. Числовые последовательности оказались полным провалом, и остальная часть вопросов, использующих словесные или числовые задачи, также не удалась.
Что еще хуже, многие ответы не имели никакого отношения к вопросам. Однако, просмотрев рассуждения модели, я увидел интересную картину. Возьмем два вопроса ниже в качестве примера.

Модель выдала правильные ответы на эти вопросы, но предоставила совершенно нерелевантную информацию. (Изображение: CGPBooks)
Ответы, выданные моделью, представляли собой идентичную (и нерелевантную) числовую последовательность для обоих вопросов. Но вот что интересно: рассуждения модели остаются в контекстном окне после получения ответов.
Модель выдала следующий ответ для вопроса 6. Он довольно длинный, но точно соответствует типу расчетов, которые сделал бы ребенок, выполняющий этот тест:
"Нам нужно посчитать, сколько предметов каждый покупает. У нас есть 5 человек. Мы должны вывести, что есть у каждого человека.
Данная информация:
У Молли, Наоми и Джейми есть чипсы.
Махмуд выбирает пирог и гороховое пюре.
Рыбу ест только Молли. Значит, у Молли есть рыба.
У Джейми, Луизы и Наоми есть сосиска. Значит, у каждого из этих троих есть сосиска.
Все едят гороховое пюре со своей едой, кроме Джейми и Молли. Значит, у Джейми и Молли нет горохового пюре. Значит, у Махмуда есть гороховое пюре (дано). У Наоми есть гороховое пюре? Подождите, "все едят гороховое пюре, кроме Джейми и Молли", что означает, что все, кроме них, едят гороховое пюре. Значит, у Наоми, Луизы, Махмуда есть гороховое пюре. Но у Наоми уже есть чипсы, сосиска, гороховое пюре. У Луизы есть сосиска, чипсы? Подождите, не указано, но вероятно. Давайте перечислим:
Махмуд: пирог, гороховое пюре. У него есть чипсы? Не указано. У него может быть что-то еще. Мы знаем, что у него нет чипсов? Не упоминается. Но может и не быть. У нас есть ограничения.
Джейми: чипсы, сосиска. Нет горохового пюре, нет рыбы. Может быть что-то еще? Не указано.
Луиза: сосиска. Не упомянуты чипсы, но могут быть чипсы. Может быть гороховое пюре? Да, потому что у всех, кроме Джейми и Молли, есть гороховое пюре, значит, у Луизы есть гороховое пюре. И, возможно, чипсы? Но мы не указали.
Наоми: чипсы, сосиска, гороховое пюре. Нет рыбы? Не указано. И, возможно, чипсы.
Молли: чипсы, рыба, нет горохового пюре. И, возможно, сосиска? Не дано. Но "у Джейми, Луизы и Наоми есть сосиска", только у этих троих. Значит, у Молли нет сосиски. Значит, у нее есть чипсы, рыба, может быть гороховое пюре? Нет.
Теперь мы должны посчитать количество предметов, которые каждый покупает. Предметы: чипсы, гороховое пюре, рыба, сосиска, пирог. И, возможно, другие.
Давайте перечислим каждого:
Махмуд: пирог, гороховое пюре. Это 2 предмета. Мог ли он также иметь чипсы? Не упомянуто. Но мы не можем предполагать. Нам нужно вывести из "У всех есть гороховое пюре со своей едой, кроме Джейми и Молли." Это включает всех, кроме них. Значит, да, у Махмуда есть гороховое пюре. А пирог отдельно. Значит, 2 предмета.
Джейми: чипсы, сосиска. Нет горохового пюре. Значит, 2 предмета.
Луиза: сосиска, гороховое пюре. Также чипсы? Не указано. Могут быть чипсы? Если бы у нее были чипсы, это было бы 3 предмета. Но никакой информации не запрещает. Но мы должны посмотреть, есть ли какие-либо другие ограничения: "У Молли, Наоми и Джейми есть чипсы." Это говорит о том, что только у этих троих есть чипсы? Подождите, предложение: "У Молли, Наоми и Джейми есть чипсы." Это явно говорит о том, что у этих троих есть чипсы. Говорит ли это о том, что у других нет чипсов? Не обязательно. Но типичный тест может подразумевать, что только у этих троих есть чипсы. Но неоднозначно. Обычно фраза "У Молли, Наоми и Джейми есть чипсы" означает, что у этих троих есть чипсы; у других может быть или не быть. Но следующие утверждения: "У Джейми, Луизы и Наоми есть сосиска." Это указывает на то, что у Луизы есть сосиска; но ничего не упоминается о чипсах для Луизы. Однако, если мы интерпретируем, что только у этих троих есть чипсы, то у Луизы нет чипсов. Значит, у Луизы есть сосиска и гороховое пюре, это 2 предмета. Но если бы у Луизы были чипсы, то 3 предмета, но не дано.
Нам нужно найти, кто покупает больше всего предметов. Давайте оценим возможности.
Случай A: У Луизы НЕТ чипсов. Тогда у каждого человека по 2 предмета: у Махмуда 2, у Джейми 2, у Луизы 2, у Наоми 3? У Наоми есть чипсы, сосиска, гороховое пюре => 3 предмета. У Молли есть чипсы, рыба => 2 предмета. Значит, у Наоми больше всего (3). Случай B: У Луизы есть чипсы: тогда у Луизы 3 предмета; у Наоми 3 предмета; у других 2. Ничья. Но нам нужен уникальный ответ. Вероятно, ответ - Наоми.
Таким образом, ответ: Наоми.
Но нам нужно проверить: Может ли у кого-то быть больше 3? Маловероятно.
Таким образом, ответ на вопрос 6: Наоми."
Аналогично, модель вывела правильный ответ на следующий вопрос, но выдала совершенно нерелевантный ответ.
Еще один интересный момент, который я заметил в рассуждениях, заключается в том, что когда модель "застревает", она предлагает пропустить вопрос и двигаться дальше. В своих окончательных рассуждениях, где она генерирует ответы, она сказала следующее:
"Это неудовлетворительно.
Учитывая, что это нереалистично, возможно, ответ не ожидается.
Таким образом, я бы ответил, что это слишком долго.
Но я должен предоставить все. Но я застрял.
Учитывая время, я предоставлю частичный ответ и заявлю, что не могу решить все.
Давайте сделаем это."
Проблема в том, что вместо того, чтобы следовать своим рассуждениям, модель просто выдавала случайные ответы. У меня есть предположение, почему это происходило, о чем я расскажу ниже.
Повторное тестирование с учетом полученных знаний
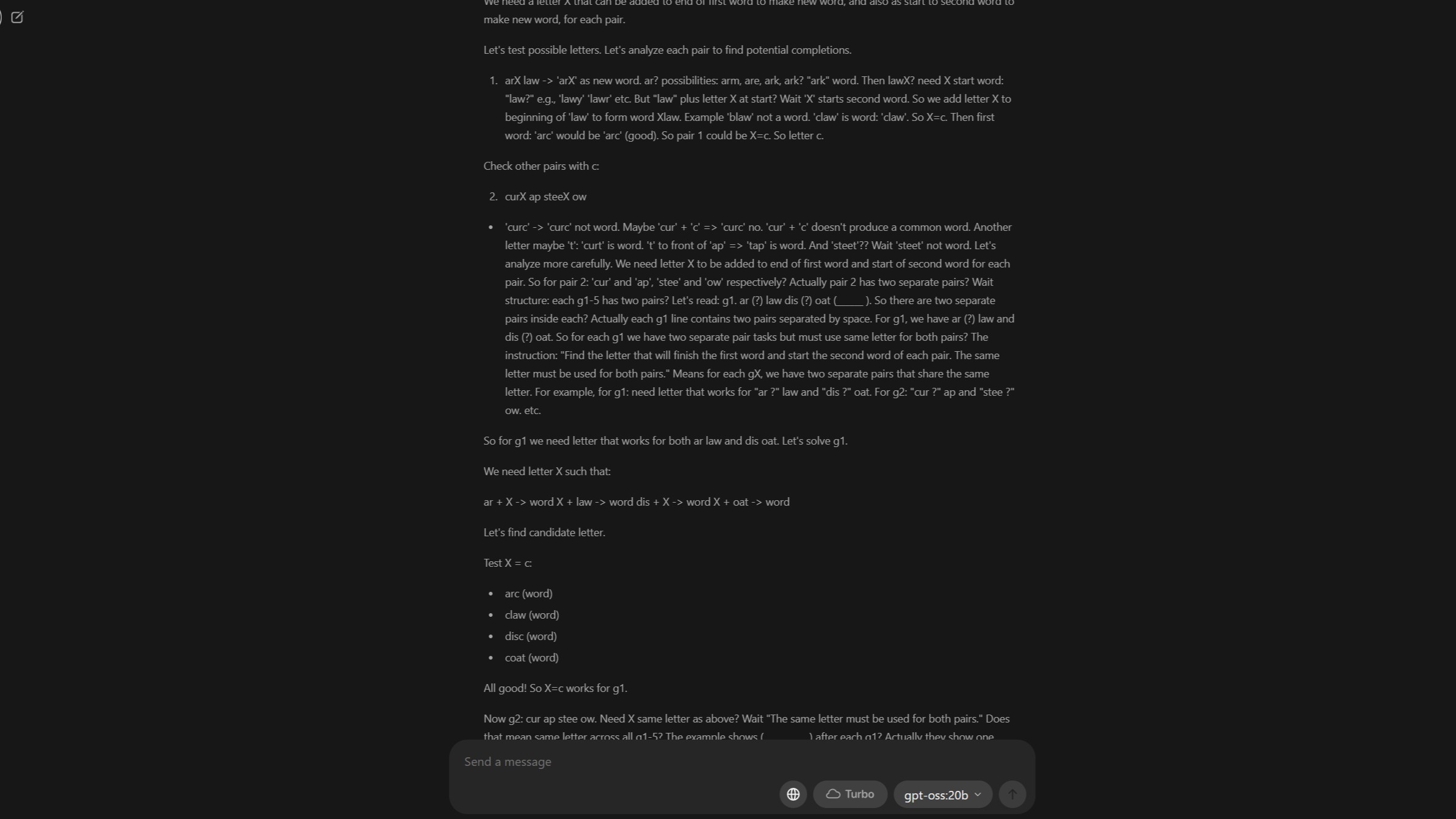
Самое замечательное в gpt-oss:20b - это возможность просмотреть ее рассуждения. Это пример решения задачи, несмотря на то, что в итоге она не выдала правильный ответ. (Изображение: Windows Central)
Подчеркну, что я не ожидал получить 100% правильный ответ. Я вообще ничего не ожидал. Но я кое-чему научился.
Во-первых, я понял, что мои первоначальные настройки были неоптимальными. Поэтому я снова запустил тест, увеличив длину контекста в Ollama, предположив, что именно это было причиной неудач.
На этот раз модели потребовался почти час, который детям отводится на выполнение теста, чтобы завершить свои рассуждения. Результаты оказались гораздо лучше: модель ошиблась только в одном из первых 12 вопросов. Кроме того, она лучше справилась с вопросами, связанными с числовыми последовательностями, которые провалила в первом запуске.
Однако на этот раз возникла другая проблема: вместо того, чтобы выдавать ответы, которые она явно правильно находила в процессе рассуждений, модель снова выдавала бессмысленный набор символов.
Вместо ответов она создала свою собственную викторину в том же стиле, что и тест. Рассуждения модели казались частично успешными, даже несмотря на то, что это заняло почти час, но вывод полностью игнорировал первоначальную подсказку.
Как урок для себя, я понял, что для обработки больших документов, таких как этот тест, критически важен объем "памяти", доступной модели.
Выводы и наблюдения

У кого-нибудь есть пара запасных серверных стоек, которые я могу одолжить? (Изображение: Getty Images | quantic69)
Изначально это был просто эксперимент, чтобы проверить, сможет ли gpt-oss:20b успешно интерпретировать PDF-файл. В этом плане эксперимент можно считать успешным: модель прочитала файл и попыталась выполнить то, что я просил.
Первый запуск, вероятно, был ограничен длиной контекста. Модели просто не хватило "памяти", чтобы выполнить задачу. Второй запуск, который занял гораздо больше времени, был более успешным.
Я не пробовал запускать тест с максимальной длиной контекста 128k, которую сейчас поддерживает Ollama. Частично потому, что у меня нет времени, а частично потому, что я не уверен, что мое оборудование справится с такой задачей.
RTX 5080 с "всего" 16 ГБ VRAM не совсем подходит для этой модели. Видеокарта работала на пределе, и часть нагрузки взял на себя процессор. Несмотря на то, что gpt-oss:20b меньше, чем некоторые другие доступные модели, она все еще слишком велика для использования на игровом ПК.
При запуске gpt-oss:20b на моей системе GPU выполнял только 65% работы, остальное брал на себя процессор. Тем не менее, я впечатлен способностями модели к рассуждению.
Для обеспечения высокой производительности я в последнее время в основном использую Gemma3:12b. (Изображение: Windows Central)
Эта модель также довольно медленная. Опять же, это может быть связано с моим оборудованием, но кажется, что она применяет рассуждения к каждой подсказке. Я спросил ее, какой у нее предел знаний, и она потратила 18 секунд на размышления, прежде чем дать ответ, проанализировав все возможные объяснения.
Это, конечно, имеет свои преимущества. Но если вам нужна быстрая модель для домашнего использования, стоит поискать что-то другое. Gemma3:12b - моя любимая модель прямо сейчас, когда речь идет о производительности на моем оборудовании.
Итак, что можно сказать о реальном тесте? В каком-то смысле он состоялся. Выиграла ли модель? Определенно нет, и мой 10-летний ребенок может спать спокойно, зная, что он все еще "умнее", чем эта модель искусственного интеллекта. Я могу с уверенностью сказать, что, экспериментируя с этой и другими моделями, я создаю свою собственную базу знаний.
И это не может не радовать, даже если запуск этих моделей превратил мой офис в сауну.
Мнение редакции MSReview: Тестирование новых LLM на задачах, разработанных для детей, - интересный способ оценить их способности к рассуждению и пониманию. Хотя в данном случае gpt-oss:20b не превзошла 10-летнего ребенка, важно помнить, что эти модели постоянно развиваются, и их производительность будет только улучшаться.






TipTop.org — это удобный сервис для заработка, где заказчики размещают оплачиваемые проекты и задания. Система позволяет начать работу с выполнения простых заказов как новичкам, так и продвинутые возможности по публикации услуги для профессиональных фрилансеров

МоиПесни.рф — онлайн-сервис, который с помощью нейросети за пару минут создает уникальные песни по вашему сценарию: поздравления, любовные треки, шутливые куплеты и многое другое. Просто опишите повод и героя, выберите стиль — и получите готовую песню с текстом и вокалом.
- Комментарии