Секрет быстрого локального ИИ: почему объем видеопамяти (VRAM) важнее всего
- Категория: AI Технологии
- Дата: 25 августа 2025 г. в 17:15
- Просмотров: 319

Ollama — это простой способ попробовать большие языковые модели (LLM) для локального ИИ на вашем компьютере. Но есть один нюанс, который важнее всего остального: видеопамять (VRAM).
Возможно, вы удивитесь, но для локального ИИ старая видеокарта RTX 3090 может оказаться полезнее, чем, например, новая RTX 5080. В играх новая карта, безусловно, будет лучше. Но для задач ИИ у "старой лошадки" есть одно неоспоримое преимущество — больше видеопамяти.
VRAM — король, если вы хотите запускать LLM локально

Несмотря на то, что новые поколения графических процессоров мощнее, без достаточного объема VRAM эта мощность окажется бесполезной для локального ИИ.
Новая RTX 5060 будет превосходить RTX 3060 в играх, но у старой карты 12 ГБ VRAM, а у новой всего 8 ГБ. И для ИИ это критично.
Ollama требует, чтобы вы могли загрузить LLM целиком в эту "быструю" видеопамять для достижения максимальной производительности. Если VRAM не хватает, данные начинают перетекать в системную память, и центральный процессор (CPU) берет на себя часть нагрузки. В результате производительность резко падает.
Тот же принцип действует, если вы используете LM Studio вместо Ollama, даже со встроенным графическим процессором (iGPU). Чем больше памяти зарезервировано для графического процессора, тем лучше. Это позволит загрузить LLM и избежать подключения ЦП.
Графический процессор + видеопамять = максимальная производительность!
Как понять, сколько VRAM вам нужно? Очень просто: посмотрите, сколько "весит" модель. Например, в Ollama модель gpt-oss:20b занимает 13 ГБ после установки. Вам нужно как минимум столько же видеопамяти, чтобы ее загрузить.
В идеале, нужен еще и запас, поскольку для более крупных задач и контекстных окон требуется дополнительное место (кэш KV). Многие рекомендуют умножать размер модели на 1.2, чтобы получить более точную оценку необходимого объема VRAM.
Этот же принцип применяется, если вы резервируете память для iGPU в LM Studio.
Недостаток VRAM = падение производительности
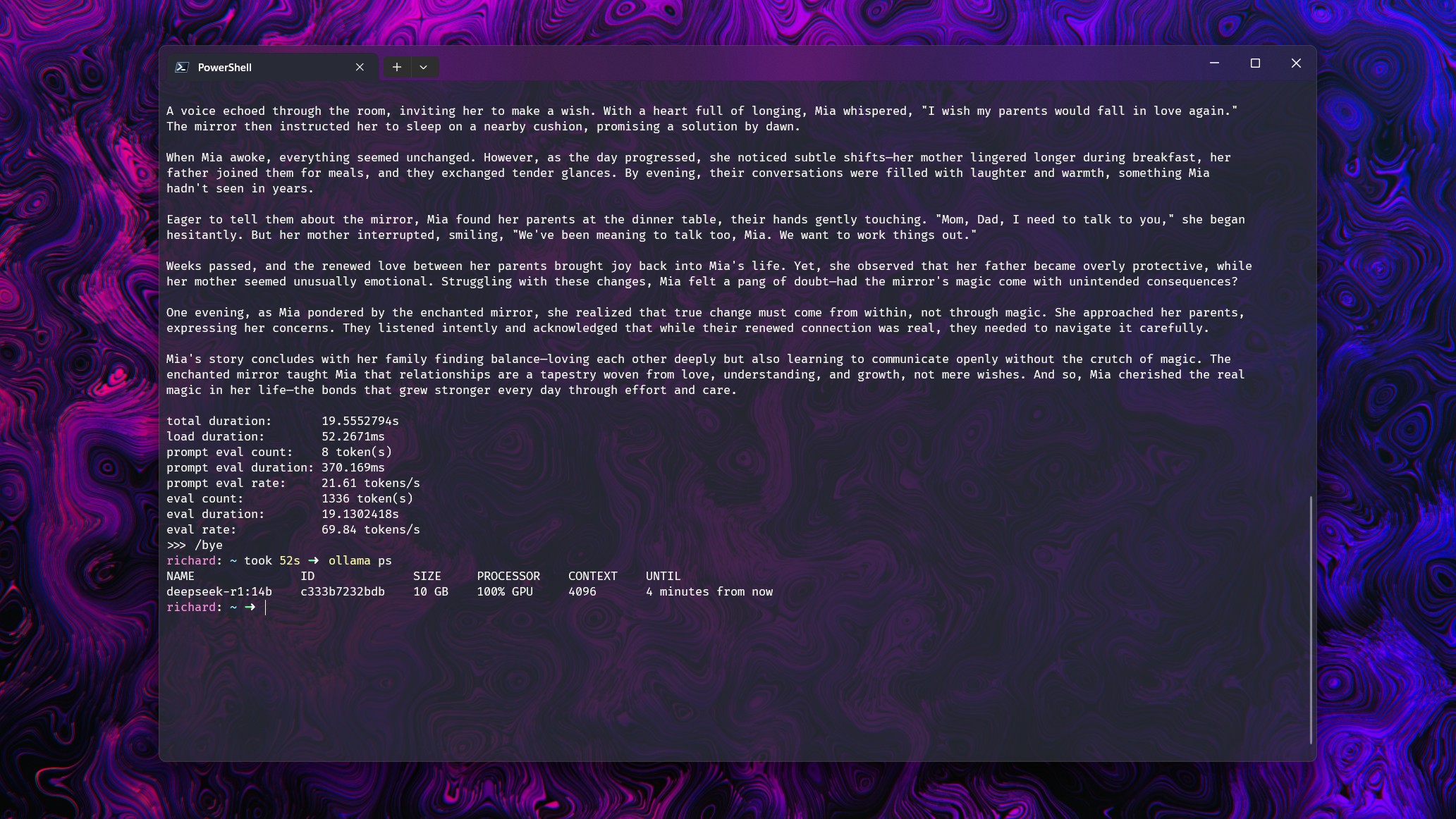
Давайте рассмотрим несколько примеров, чтобы проиллюстрировать эту идею. Был проведен простой тест: модели попросили рассказать короткую историю, используя RTX 5080. Во всех случаях модели полностью загружались в доступные 16 ГБ VRAM.
Тестовая система также включала процессор Intel Core i7-14700k и 32 ГБ оперативной памяти DDR5 6600.
Контекстное окно каждой модели было увеличено, чтобы заставить Ollama использовать системную оперативную память и ЦП. Это позволило увидеть, насколько сильно падает производительность.
Вот результаты:
- Deepseek-r1 14b (9 ГБ): С контекстным окном до 16k, загрузка графического процессора составляет 100% при скорости около 70 токенов в секунду. При 32k происходит разделение: 21% ЦП и 79% графического процессора, а производительность падает до 19.2 токенов в секунду.
- gpt-oss 20b (13 ГБ): С контекстным окном до 8k, загрузка графического процессора составляет 100% при скорости около 128 токенов в секунду. При 16k происходит разделение: 7% ЦП и 93% графического процессора, а производительность падает до 50.5 токенов в секунду.
- Gemma 3 12b (8.1 ГБ): С контекстным окном до 32k, загрузка графического процессора составляет 100% при скорости около 71 токена в секунду. При 32k происходит разделение: 16% ЦП и 84% графического процессора, а производительность падает до 39 токенов в секунду.
- Llama 3.2 Vision (7.8 ГБ): С контекстным окном до 16k, загрузка графического процессора составляет 100% при скорости около 120 токенов в секунду. При 32k происходит разделение: 29% ЦП и 71% графического процессора, а производительность падает до 68 токенов в секунду.
Это не самое научное тестирование, а скорее иллюстрация. Когда графический процессор не справляется в одиночку, и в дело вступает остальная часть компьютера, производительность LLM значительно снижается.
Этот тест показывает, насколько важно иметь достаточно видеопамяти, чтобы LLM работали наилучшим образом. Необходимо избегать ситуаций, когда ЦП и оперативная память вынуждены "подхватывать" задачу.
В данном случае, производительность все еще оставалась приличной, но это благодаря хорошему "железу", поддерживающему графический процессор.
Рекомендуется иметь не менее 16 ГБ VRAM, если вы хотите запускать модели уровня gpt-oss:20b. А 24 ГБ будет еще лучше, если вам нужно место для более интенсивных задач.
Мнение редакции MSReview: Для локального запуска больших языковых моделей (LLM), таких как GPT-OSS:20b, объем видеопамяти (VRAM) является критически важным фактором. Недостаток VRAM может привести к значительной потере производительности, так как системе придется использовать оперативную память и ЦП для компенсации, что значительно замедлит процесс. Рекомендуется иметь как минимум 16 ГБ VRAM для работы с моделями среднего размера, а для более требовательных задач лучше стремиться к 24 ГБ или более. Важно учитывать не только размер модели, но и контекстное окно, которое также требует дополнительной VRAM.






TipTop.org — это удобный сервис для заработка, где заказчики размещают оплачиваемые проекты и задания. Система позволяет начать работу с выполнения простых заказов как новичкам, так и продвинутые возможности по публикации услуги для профессиональных фрилансеров

МоиПесни.рф — онлайн-сервис, который с помощью нейросети за пару минут создает уникальные песни по вашему сценарию: поздравления, любовные треки, шутливые куплеты и многое другое. Просто опишите повод и героя, выберите стиль — и получите готовую песню с текстом и вокалом.
- Комментарии